DeepLocalizer: A Library to Find Functional Specialization in Deep Neural Networks
Python library to find function specific activations in artificial neural networks using fMRI-like localization.
Blog
This is a short report extending the paper "The LLM Language Network: A Neuroscientific Approach for Identifying Causally Task-Relevant Units" [1] to Image Classification models.
Motivation
I thought [1] was a neat paper and I wanted to see if I could apply the same techniques to a Resnet [2] model.
Just some background: they [1] specifically used fMRI localization methods to localize the language network in LLMs. Some more intuition: you can localize language function by contrasting brain imaging of a person reading sentences against a control of reading non-words (see [3], [4], and [5] for more). The idea being you find activations specific to one function and not the other (hence subtracting out the control). They simply used artificial neural network activations instead of brain imaging.
I applied the same technique, but to image classification models. I asked the question: is there a network that only processes faces in a Resnet [2] image classification model?
I created a face localizer dataset that uses images from the CelebA face dataset [7] as the positive stimulus and images from the COCO objects dataset [8] as the negative control.

I used 2000 images of faces (subset shown above) and 2000 images of object-dominated images to localize the face network in Resnet. And I have some preliminary results that show it indeed only processes faces.
Activations
Like I said before, I used the same methods in [1], but with some modifications. I implemented everything from scratch and in PyTorch [6].
I used a pretrained Resnet34 model from [2] and extracted activations for each data image input from every residual skip connection (see figure below). This would be roughly analogous to showing an image to a person and scanning their brain for activations. Then doing this for all the images in the face localization dataset.

There were 2000 face images and 2000 object images. So in total, I ran the model on 4000 images. I accumulated activations by averaging over all face image activations, then averaging over all object image activations, then subtracting out the object image activations (control) from the face image activations.
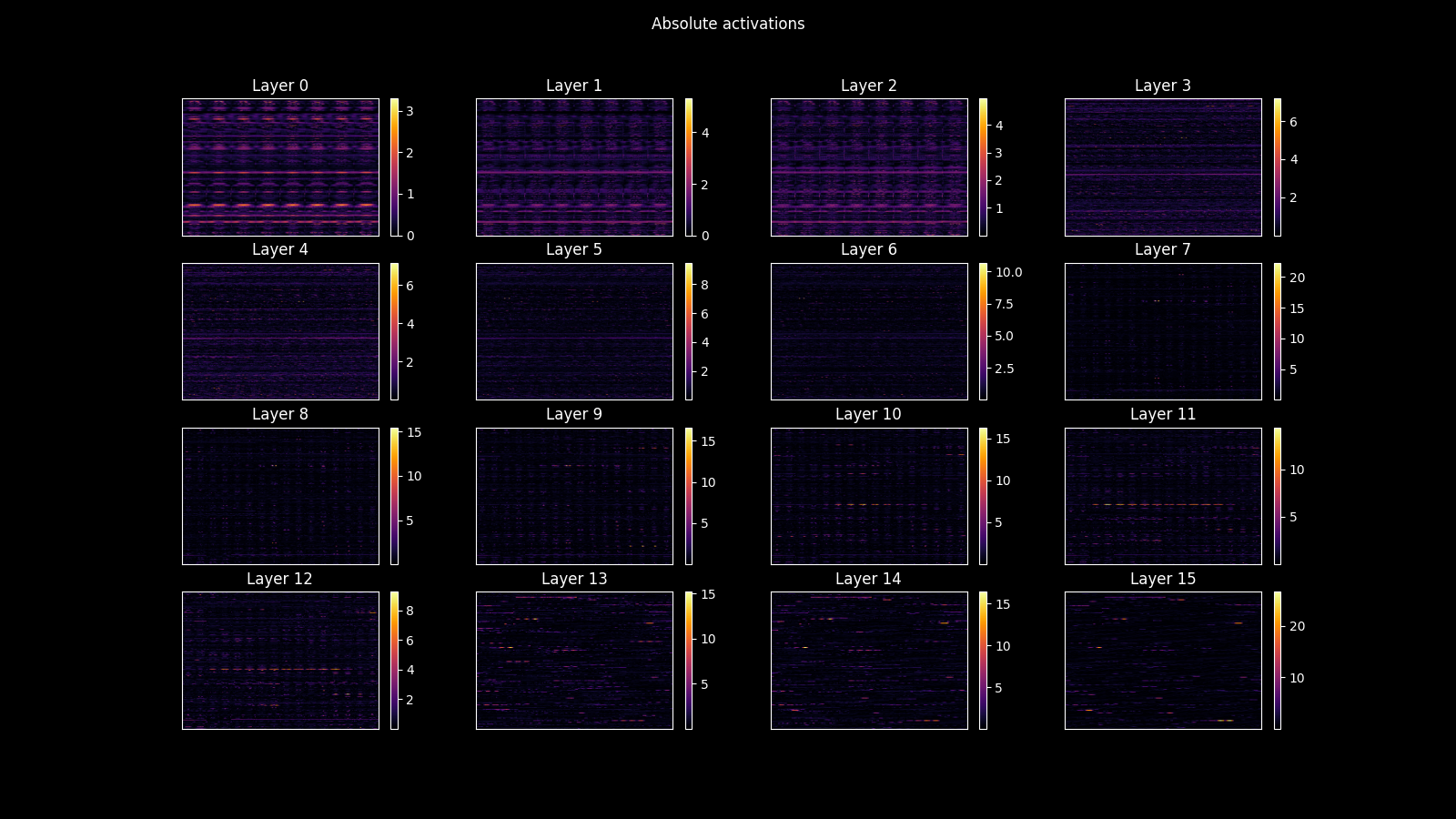
The result are activations that selectively fired for face images in my face localizer dataset. See the figure below for what these localized activations looked like for each extracted layer.
Analysis
The top activations are more likely to only fire when faces are present. So just like [1] did, I considered the top percent of activations as part of the network.
I ended up taking the top half percent (0.5%) of activations which looks like the figure below. But I tried a few different thresholds (more on this later).
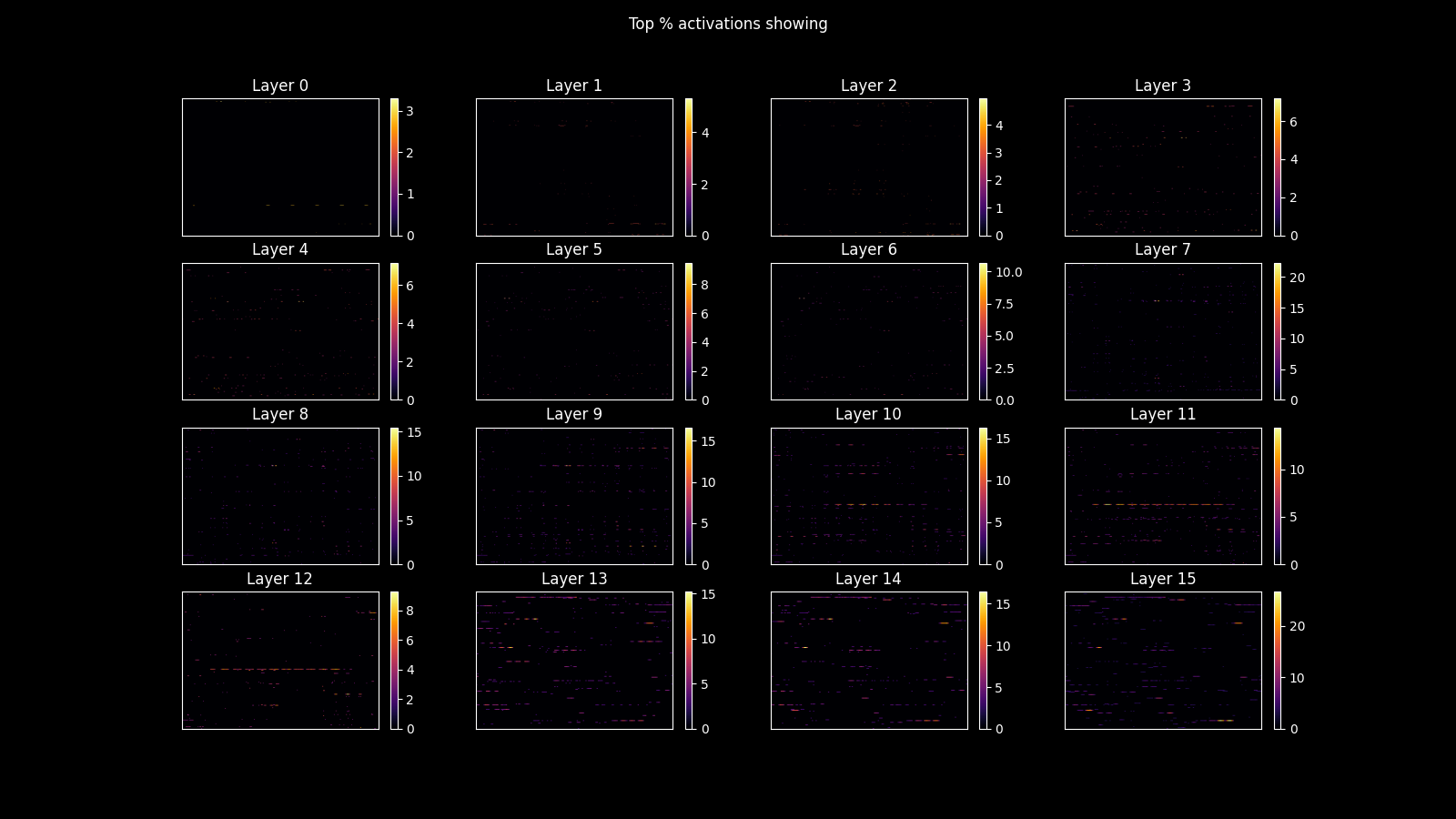
You can eyeball it, but just to be explicit, most of the top 0.5% of activations can be found in the last layers. This somewhat lines up with the fact that neural networks process higher-level concepts in earlier layers (shapes, edges, etc.) and more detailed concepts in later layers.
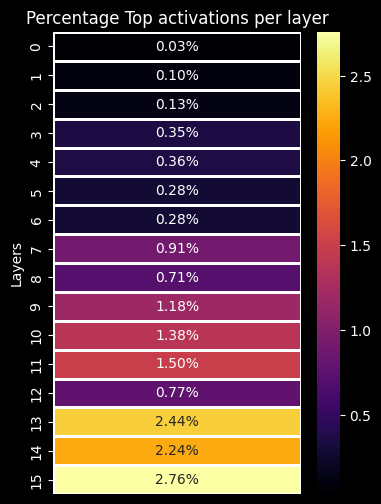
Next, I'll provide some ablation/lesion evidence that this top 0.5% of activations constitutes only face processing.
I took 1000 face images and 1000 object images not used during the localization process (unseen validation data) and ran them through the original model. Then, I took the same images and ran them through the model with the top 0.5% of activations ablated/lesioned out.
I used relative performance change and KL divergence metrics between the original model and ablated model as evidence of the face network. Specifically, I compared the original predictions to the ablated predictions for face images.
For faces, I found that only 2.6% of predictions stayed the same between the original and ablated models predictions. In other words 97.4% of predictions changed for face images. Contrast this data with the object images (control). For object images, 73.5% of predictions stayed the same after ablation. Or 26.5% of predictions changed.
To quantify how much the probability distributions of predictions changed, I used mean KL divergence between the ablated model and the original model to measure distance between distributions. With the intuition being that if the KL divergence is high, the predictions are wildly different than in the original model, and likely very wrong. The mean KL for the face images was 3.1148 while only 0.204265 for the control objects. Suggesting that ablation drastically changed how the model predicts faces, but not to a large extent objects.
I also computed these relative performance metrics for different thresholds of activations (which led me to picking 0.5%). I tried ablating 0.0625% (1/16), 0.125% (1/8), 0.25% (1/4), 0.5% (1/2), and 1% just like [1] did.

Based on the performance above, I decided 0.5% was a reasonable threshold to pick to localize the face network.
Conclusion
I can say there is evidence of a network that processes only faces in Resnet34, although more evidence is needed to say for sure.
What is also interesting is that Resnet was trained on Imagenet1k images and labels where there are no explicit labels for humans or faces. There are labels for things on humans (like neckbrace, wig, etc.), but not specific human facial features. So this is either a confound, or suggests that the network learned to process faces without explicit labels.
To reproduce the results in this blog, see resnet34_example.ipynb.